http://habrahabr.ru/post/103107/

Статья рассматривает алгоритм поиска и описания особых точек изображения SURF. Метод может применяться для сравнения изображений, поиска объектов на изображениях, 3D реконструкции.
Задача распознавания образов до сих пор не решена в полном объеме. Однако, в рамках существенных ограничений, есть методы, позволяющие приблизится к ее решению.
Среди различных родственных методов, был выбран для рассмотрения метод Speeded Up Robust Features (SURF), поскольку он является одним из самых эффективных и быстрых современных алгоритмов. Кроме того, SURF является распространенным методом, его реализации есть во многих математических библиотеках.
В первой части я опишу проблему в целом и обобщенные пути решения.
В дальнейшем описании я постараюсь придерживаться именно SURF, не отвлекаясь на родственные алгоритмы и не углубляясь в теоретическую базу. Вторая часть статьи скорее отвечает на вопрос «как оно работает?», чем на вопрос «почему этот алгоритм именно такой?». Теоретические обоснования можно почерпнуть из первоисточника, а также из списка литературы, приведенного в конце статьи.
Когда мы смотрим на окружающих нас лица людей, предметы, природу, мы не осознаем какой объем работы проделывает наш мозг, что бы обработать весь поток визуальной информации. Нам не составит труда найти знакомого нам человека на фотографии, или отличить здание от памятника. Казалось бы, наши компьютеры отлично могут хранить огромные объемы информации, картинки, видео и аудио файлы. Что мешает им с такой же легкостью найти фото нашего любимого человека из личной фотогалереи? Этому препятствует ряд моментов, которые мы здесь и перечислим.
Момент первый: Масштаб. Изображения имеют разный масштаб. Предметы, которые мы воспринимаем как одинаковые, на самом деле занимают разную площадь на разных изображениях.
Момент второй: Место. Интересующий нас объект может находиться в разных местах изображения.
Момент третий: Фон и помехи. Предмет, который мы воспринимаем как что-то отдельное, на изображении никак не выделен, и находится на фоне других предметов. Кроме того, изображение не идеально и может быть подвержено всякого рода искажениям и помехам.
Момент четвертый: Проекция, вращение и угол обзора. Изображение является лишь двумерной проекцией нашего трехмерного мира. Поэтому поворот объекта и изменение угла обзора кардинальным образом влияют на его двумерную проекцию — изображение. Один и тот же объект может давать совершенно разную картинку, в зависимости от поворота или расстояния до него.
Список можно было-бы продолжать еще долго. Но мы не будем этого делать.
Итак, даны два изображения, один из них будем считать образцом, другое – сценой. Задача сводится к определению факта наличия образца на сцене, и к его локализации. При этом образец на сцене может:
a) иметь другой масштаб
б) быть повернут в плоскости изображения
в) быть в произвольном месте сцены
г) может быть зашумлен, виден не полностью, частично заслонен другими предметами
д) может иметь отличную от образца яркость и контраст
е) его может не быть совсем
Возможны, конечно, и другие варианты. Однако мы будем решать только перечисленные пункты. Например, мы НЕ будем рассматривать вращение объекта вокруг произвольной оси. Поиск образца Софийского собора, но «с обратной стороны» — также выходит за рамки наших требований.
Но перейдем от задач к решениям.
Не отвлекаясь на различные подходы к решению очерченных выше проблем сравнения образов, выберем один из них.
Самое простое и тривиальное решение заключается в следующем: возьмем образец в разных масштабах, повернем его на всевозможные углы, переберем всевозможные места на сцене, и будем все эти шаблоны попиксельно сравнивать со сценой.
Решение, как несложно понять, хорошее, но нереализуемое. И вот почему. Пусть образец и сцена имеют типичные размеры — порядка сотен пикселов по вертикали и горизонтали. Посчитав общее число всевозможных шаблонов, их поворотов, масштабов и локализации, а также умножив на число операций попиксельного сравнения, получим около триллиона (10^12) операций для поиска и локализации образца на сцене. Для какого нибудь Roadrunner это может и пустяки, но наши CoreDuo пока явно не дотягивают до такой производительности.
Кроме того, непосредственное сравнение образца со сценой может дать плохой результат, из-за шумов, искажений, заслонения, объектов фона.
Поэтому мы поступим хитрее. Выделим на образце некие ключевые точки и небольшие участки вокруг них. Ключевой точкой будем считать такую точку, которая имеет некие признаки, существенно отличающие ее от основной массы точек. Например, это могут быть края линий, небольшие круги, резкие перепады освещенности, углы и т.д. Предполагая, что ключевые точки присутствуют на образце всегда, то можно поиск образца свести к поиску на сцене ключевых точек образца. А поскольку ключевые точки сильно отличаются от основной массы точек, то их число будет существенно меньше, чем общее число точек образца.
В целом, принцип выбора ключевых точек не важен. Главное что бы их было не слишком много и они присутствовали на изображении образца всегда.
А почему вокруг точек выделяются малые участки? А вот почему. Чем меньше участок, тем меньше на него влияют крупномасштабные искажения. Так, если объект в целом, подвержен эффекту перспективы (то есть ближний край объекта имеет больший видимый размер, чем дальний), то для малого его участка явлением перспективы можно пренебречь и заменить на изменение масштаба. Аналогично, небольшой поворот объекта вокруг некоторой оси может сильно изменить картинку объекта в целом, но малые участки изменятся чуть-чуть.
Кроме того, если часть объекта выходит за край изображения или заслонена, то небольшие участки вокруг части ключевых точек будут видны целиком, что также позволяет их легче идентифицировать. А еще, если малые области лежат целиком внутри искомого объекта, то на них не оказывают никакого влияния объекты фона.

На рисунке показаны особые точки изображения в образце(слева) и на сцене(справа). Несмотря на то, что сцена имеет другой масштаб, угол обзора и частично заслонена другим объектом, ключевые точки достаточно точно идентифицируются.
С другой стороны, участок вокруг ключевой точки не должен быть слишком мал. Очень малые участки несут слишком мало информации об изображении и с большей вероятностью могут случайно совпадать между собой.
SURF решает две задачи – поиск особых точек изображения и создание их дескрипторов, инвариантных к масштабу и вращению. Это значит, что описание ключевой точки будет одинаково, даже если образец изменит размер и будет повернут (здесь и далее мы будем говорить только о вращении в плоскости изображения). Кроме того, сам поиск ключевых точек тоже должен обладать инвариантностью. Так, что бы повернутый объект сцены имел тот же набор ключевых точек, что и образец.
Метод ищет особые точки с помощью матрицы Гессе. Детерминант матрицы Гессе (т.н. гессиан) достигает экстремума в точках максимального изменения градиента яркости. Он хорошо детектирует пятна, углы и края линий.

На картинке – особые точки изображения здания, найденные с помощью матрицы Гессе. Диаметр круга показывает масштаб особой точки. Зеленая линия – направление градиента яркости.
Гессиан инвариантен относительно вращения. Но не инвариантен масштабу. Поэтому SURF использует разномасштабные фильтры для нахождения гессианов.
Для каждой ключевой точки считается направление максимального изменения яркости (градиент) и масштаб, взятый из масштабного коэффициента матрицы Гессе.
Градиент в точке вычисляется с помощью фильтров Хаара.
После нахождения ключевых точек, SURF формирует их дескрипторы. Дескриптор представляет собой набор из 64(либо 128) чисел для каждой ключевой точки. Эти числа отображают флуктуации градиента вокруг ключевой точки (что понимается под флуктуацией — рассмотрим ниже). Поскольку ключевая точка представляет собой максимум гессиана, то это гарантирует, что в окрестности точки должны быть участки с разными градиентами. Таким образом, обеспечивается дисперсия (различие) дескрипторов для разных ключевых точек.
Флуктуации градиента окрестностей ключевой точки считаются относительно направления градиента вокруг точки в целом (по всей окрестности ключевой точки). Таким образом, достигается инвариантность дескриптора относительно вращения. Размер же области, на которой считается дескриптор, определяется масштабом матрицы Гессе, что обеспечивает инвариантность относительно масштаба.
Флуктуации градиента также считаются с помощью фильтра Хаара.
Для эффективного вычисления фильтров Гессе и Хаара – используется интегральное представление изображений.
Если кратко, то интегральное представление является матрицей, размерность которой совпадает с размерностью исходного изображения, а элементы считаются по формуле:
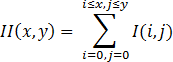
Где I(i,j) – яркость пикселов исходного изображения.
Имея интегральную матрицу можно очень быстро вычислять сумму яркостей пикселов произвольных прямоугольных областей изображения, по формуле:
SumOfRect(ABCD) = II(A) + II(С) — II(B) — II(D)
Где ABCD – интересующий нас прямоугольник.
Обнаружение особых точек в SURF основано на вычислении детерминанта матрицы Гессе (гессиана).
Матрица Гессе для двумерной функции и ее детерминант определяется следующим образом:
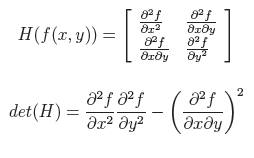
Значение гессиана используется для нахождения локального минимума или максимума яркости изображения. В этих точках значение гессиана достигает экстремума.
На картинке видно, что особые точки (очерченные цветными кругами) представляют собой локальные экстремумы яркости изображения. Мелкие точки не распознаны как особые, из-за порогового отсечения по величине гессиана.

На рисунке показаны концы отрезка, распознанные как ключевые точки, с помощью матрицы Гессе.
Теоретически, вычисление матрицы Гессе сводится к нахождению Лапласиана Гауссиан. По сути, элементы матрицы Гессе вычисляются как свертка (сумма произведений) пикселов изображения на фильтры, изображенные на рисунке:

На рисунке изображены дискретизированные фильтры для нахождения четырех элементов матрицы Гессе (четвертый – совпадает с третьим, поскольку матрица Гессе симметрична). Фильтры имеют пространственный масштаб 9x9 пикселов. Темные участки соответствуют отрицательным значениям фильтра, светлые – положительным.
Однако, SURF не использует лапласиан гауссианы в том виде, который изображен на рисунке. Во-первых, по утверждению авторов, дискретизированный лапласиан гауссианы имеет довольно большой разброс значения детерминанта, при вращении образца (напомним, что в идеале гессиан должен быть инвариантен к вращению). Особенно детерминант «проседает» в районе поворота на 45 граудсов. А во-вторых, и это главное, фильтр для лапласиана гауссианы имеет непрерывный характер. Почти все пикселы фильтра имеют разные величины яркости. А это не позволяет эффективно использовать такой мощный механизм расчёта, как интегральную матрицу изображения.
Поэтому SURF использует бинаризированную аппроксимацию лапласиана гауссиан (авторы назвали его Fast-Hessian):
На рисунке изображены фильтры, используемые для нахождения матрицы Гессе в SURF. Белые области соответствуют значению +1, черные -2 (на третьем фильтре -1), серые – нулевые. Пространственный масштаб – 9x9 пикселов.
Этот фильтр более устойчив к вращению, и его можно эффективно вычислить с помощью интегральной матрицы.
Таким образом, в SURF, гессиан вычисляется так:

Где Dxx, Dyy, Dxy – свертки по фильтрам, изображенным на рисунке вверху. Коэффициент 0.9 имеет теоретическое обоснование, и корректирует приближенный характер вычислений.
Итак, для нахождения особых точек, SURF пробегается по пикселам изображения и ищет максимум гессиана. Способ нахождения локального максимума гессиана мы рассмотрим позднее. В методе задается пороговое значение гессиана. Если вычисленное значение для пиксела выше порога – пиксел рассматривается как кандидат на ключевую точку.
Тут еще полезно заметить следующее. Поскольку гессиан является производной, и зависит только от перепада яркости, но не от абсолютного ее уровня, то он инвариантен по отношению к сдвигу яркости изображения. Таким образом, изменение уровня освещения образца не влияет на обнаружение ключевых точек.
Кроме того, свойства гессиана таковы, что он достигает максимума, как в точке белого пятна на черном фоне, так и черного пятна на белом фоне. Таким образом, метод обнаруживает и темные, и светлые особенности изображения.

Метод распознает как светлые точки на темном фоне, так и темные точки на светлом фоне.
Как уже отмечалось, гессиан не инвариантен относительно масштаба. Это значит, что для одного и того же пиксела, гессиан может меняться при изменении масштаба фильтра. Решение этой проблемы только одно – перебирать различные масштабы фильтров и поочередно их применять к данному пикселу.
Из соображений симметрии и дискретизации, размер фильтра Fast-Hessian не может принимать произвольные значения. Допустимые размеры этого фильтра таковы (начиная с минимального): 9, 15, 21, 27 и так далее, с шагом 6. Однако, на практике, постепенно увеличивать размер фильтра на 6 — не выгодно, потому что для крупных масштабов шаг 6 оказывается слишком мелким, а фильтры — избыточными. Поэтому (и по некоторым другим причинам), SURF разбивает все множество масштабов на так называемые октавы. Каждая октава покрывает определенный интервал масштабов, и имеет свой характерный размер фильтра.
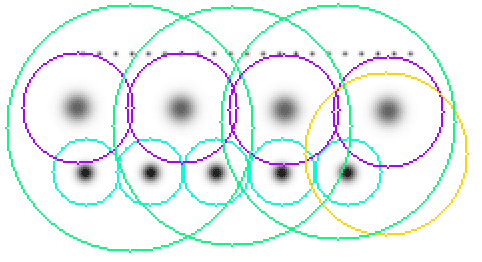
При этом если бы на октаву приходился только один фильтр, это было бы слишком грубым приближением. Кроме того, мы бы не могли найти локальный максимум гессиана, среди разных масштабов, в разных октавах. Ведь одна и та же точка может иметь несколько локальных максимумов гессиана, в разных масштабах. Это хорошо видно на картинке:

Рисунок показывает две ключевые точки разного масштаба в одной точке изображения.
Если мы будем искать максимум среди всех гессианов, по всем масштабам, то мы бы нашли только один из максимумов, в то время как их может быть несколько. Один – в одном масштабе, другой – в другом.
Исходя из перечисленного, октава содержит не один фильтр, а четыре фильтра, которые хорошо покрывают характерный масштаб октавы:

На рисунке показаны первые три октавы метода SURF. Цифры в прямоугольниках показывают размер фильтра Fast-Hessian. Логарифмическая шкала снизу – показывает масштабы, покрываемые октавами.
Шаг размера фильтра в первой октаве – составляет 6, во второй – 12, в третьей – 24 и так далее.
Как видим, октавы значительно перекрываются друг другом. Это увеличивает надежность нахождения локальных максимумов. Почему в октаве именно четыре фильтра станет ясно из следующей главы.
Возникает вопрос, а сколько собственно октав достаточно для покрытия множества особых точек разных масштабов? Теоретически, масштабы бесконечны, однако в реальных изображениях, они вполне конечны, и основная масса сосредоточена в интервале от 1 до 10 (по данным авторов метода). Для покрытия этого диапазона достаточно четырех октав. Плюс добавляется одна или две октавы для покрытия бОльших масштабов. Итого, используется 5-6 октав. Теоретически, этого вполне достаточно для покрытия всевозможных масштабов на изображении 1024x768 пикселов.
Для нахождения локального максимума гессиана, используется так называемый метод соседних точек 3x3x3.
Его смысл понятен из рисунка ниже:
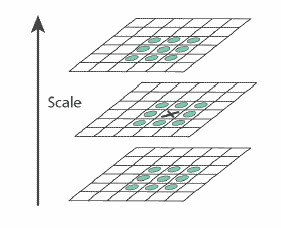
Пиксел, помеченный крестиком считается локальным максимумом, если его гессиан больше чем у любого его соседа в его масштабе, а также больше любого из соседей масштабом меньше и масштабом больше (всего 26 соседей).
Исходя из такого определения локального максимума, понятно, что октава должна содержать не менее трех фильтров, иначе мы не сможем определить факт нахождения локального максимума гессиана внутри октавы.
Отметим еще такой момент. Фильтры октавы считаются не для всех пикселов подряд. Первая октава считается для каждого второго пиксела изображения. Вторая – для каждого четвертого, третья – для каждого восьмого и так далее. Смысл понятен – две точки с расстоянием 2 не могут содержать более одного максимума масштаба 2, 3 или более высоких масштабов. Поэтому нет смысла перебирать все точки изображения, для нахождения максимума масштаба 3, например.
Удвоение шага пикселов для октав позволяет экономить при расчёте фильтров. Как вы наверно уже заметили, размеры фильтров в октавах повторяются. Так, например, фильтр размером 27 присутствует в трех октавах. Так вот, при вычислениях, этот фильтр будет считаться только для первой октавы. Вторая и третья – просто используют расчёты первой октавы. А удвоение шага пикселов гарантирует, что точки в которых нужно считать гессиан, уже были просчитаны предыдущей октавой.
Поэтому, несмотря на то, что октава содержит четыре фильтра, на самом деле каждая октава(кроме первой) считает только два характерных для нее размера, два других – всегда можно взять из предыдущих октав. Первая же октава вынуждена считать все четыре своих фильтра.
Итак, после нахождения максимального гессиана методом соседних точек 3x3x3, мы нашли пиксел в котором этот максимум достигается. Однако, поскольку, октава перебирает не все точки изображения, то истинный максимум может не совпадать с найденным пикселом, а лежать где-то рядом, в соседних пикселах.
Для нахождения точки истинного максимума, используется интерполирование найденных гессианов куба 3x3x3 квадратичной функцией. Далее, вычисляется производная (методом конечных разностей соседних точек). Если она близка к нулю – мы в точке истинного максимума. Если производная велика – сдвигаемся в сторону ее уменьшения, и повторяем итерацию, до тех пор пока производная не станет меньше заданного порога. Если в процессе итераций мы отходим от начальной точки слишком далеко, то это считается ложным максимумом, и точка больше не считается особой.
Для инвариантности вычисления дескрипторов особой точки, которые будут рассмотрены ниже, требуется определить преобладающую ориентацию перепадов яркости в особой точке. Это понятие близко к понятию градиента, но SURF использует немного другой алгоритм нахождения вектора ориентации.
Сначала, вычисляются точечные градиенты в пикселах, соседних с особой точкой. Для рассмотрения берутся пикселы в окружности радиуса 6s вокруг особой точки. Где s – масштаб особой точки. Для первой октавы берутся точки из окрестности радиусом 12.
Для вычисления градиента, используется фильтр Хаара. Размер фильтра берется равным 4s, где s – масштаб особой точки. Вид фильтров Хаара показан на картинке:

Фильтры Хаара. Черные области имеют значения -1, белые +1.
Фильтры Хаара дают точечное значение перепада яркости по оси X и Y соответственно. Поскольку фильтры Хаара имеют прямоугольную форму, их значения легко считаются с помощью интегральной матрицы. Для расчёта одного фильтра произвольного размера требуется всего 6 операций.
Значения вейвлета Хаара dX и dY для каждой точки умножаются на вес и запоминаются в массиве. Вес определяется как значение гауссианы с центром в особой точке и сигмой равной 2s. Взвешивание на гауссиане необходимо для отсечения случайных помех на далеких от особой точки расстояниях.
Далее, все найденные значения dX и dY, условно наносятся в виде точек на плоскость, как показано на рисунке:

На рисунке показаны все найденные градиенты в виде точек в пространстве dXdY.
Далее, берется угловое окно (показано серым на рисунке) размером π/3, и вращается вокруг центра координат. Выбирается такое положение окна, при котором длина суммарного вектора для попавших в окно точек – максимальна. Вычисленный таким образом вектор нормируется и принимается как приоритетное направление в области особой точки.
Манипуляции с окном нужны для уменьшения влияния шумовых точек. Ниже на рисунке приведен пример градиента при идеальном крае, и при крае с шумом:

Как видим, шум дает дополнительные градиенты в направлениях, не совпадающих с направлением основного градиента. Использование окна позволяет отсечь такие шумовые точки, и более точно вычислить истинный градиент.
Отметим, что не всегда требуется инвариантность дескрипторов относительно вращения. Метод SURF имеет модификацию, в которой ориентация особых точек не рассчитывается. Такая модификация позволяет надежно идентифицировать точки, повернутые не более чем на ±15 градусов.
Дескриптор представляют собой массив из 64 (в расширенной версии 128) чисел, позволяющих идентифицировать особую точку. Дескрипторы одной и той же особой точки на образце и на сцене должны примерно совпадать. Метод расчета дескриптора таков, что он не зависит от вращения и масштаба.
Для вычисления дескриптора, вокруг особой точки формируется прямоугольная область, имеющая размер 20s, где s – масштаб в котором была найдена особая точка. Для первой октавы, область имеет размер 40x40 пикселов. Квадрат ориентируется вдоль приоритетного направления, вычисленного для особой точки.
Дескриптор считается как описание градиента для 16 квадрантов вокруг особой точки.

Далее, квадрат разбивается на 16 более мелких квадрантов, как показано на рисунке. В каждом квадранте берется регулярная сетка 5x5 и для точки сетки ищется градиент, с помощью фильтра Хаара. Размер фильтра Хаара берется равным 2s, и для первой октавы составляет 4x4.
Следует отметить, что при расчёте фильтра Хаара, изображение не поворачивается, фильтр считается в обычных координатах изображения. А вот полученные координаты градиента (dX,dY) поворачиваются на угол, соответствующий ориентации квадрата.
Итого, для вычисления дескриптора особой точки, нужно вычислить 25 фильтров Хаара, в каждом из 16 квадрантов. Итого, 400 фильтров Хаара. Учитывая, что на фильтр нужно 6 операций, выходит, что дескриптор обойдется минимум в 2400 операций.
После нахождения 25 точечных градиента квадранта, вычисляются четыре величины, которые собственно и являются компонентами дескриптора:
∑dX, ∑|dX|, ∑dY, ∑|dY|
Две из них есть просто суммарный градиент по квадранту, а две других – сумма модулей точечных градиентов.
На рисунке показано поведение этих величин для разных участков изображений.
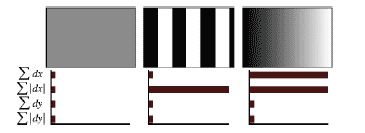
Рисунок показывает поведение дескриптора для разных изображений. Для равномерных областей – все значения близки к нулю. Для повторяющихся вертикальных полосок – все величины, кроме второй близки к нулю. При увеличении яркости в направлении оси X, две первые компоненты имеют большие значения.
Четыре компонента на каждый квадрант, и 16 квадрантов, дают 64 компонента дескриптора для всей области особой точки. При занесении в массив, значения дескрипторов взвешиваются на гауссиану, с центром в особой точке и с сигмой 3.3s. Это нужно для большей устойчивости дескриптора к шумам в удаленных от особой точки областях.
Плюс к дескриптору, для описания точки используется знак следа матрицы Гессе, то есть величина sign(Dxx+Dyy). Для светлых точек на темном фоне, след отрицателен, для темных точек на светлом фоне – положителен. Таким образом, SURF различает светлые и темные пятна.

На картинке показаны особые точки изображения. Зеленая линия показывает характерное направление для особой точки. Синий цвет окружности показывает положительный след матрицы Гессе, красный – отрицательный след.
Ниже приведен набор тестовых изображений. Первая колонка показывает изображение граффити, снятое под разным углом зрения. Вторая колонка содержит фотографии с размытием. Третья – поворот и изменение масштаба. Четвертая содержит изображения с разным уровнем яркости. Пятая – идентичное изображение, но с разным качеством сжатия JPEG.

Далее приведены результаты тестирования. По вертикали отложен процент точек, которые были правильно идентифицированы.
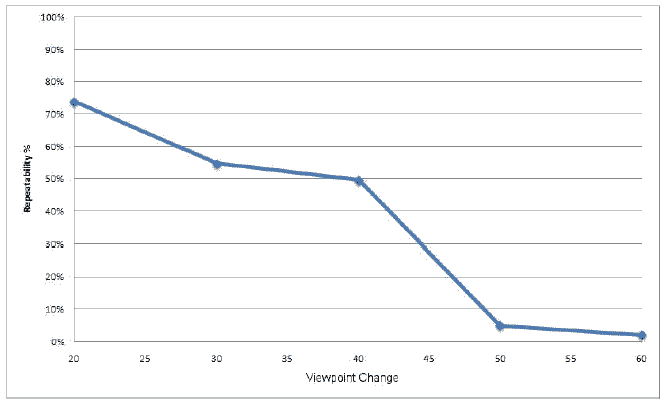
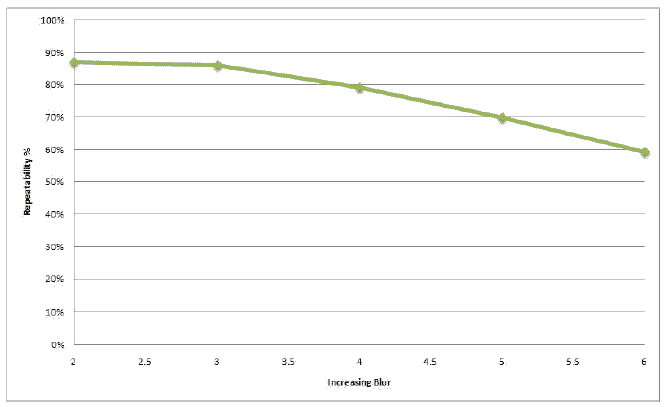
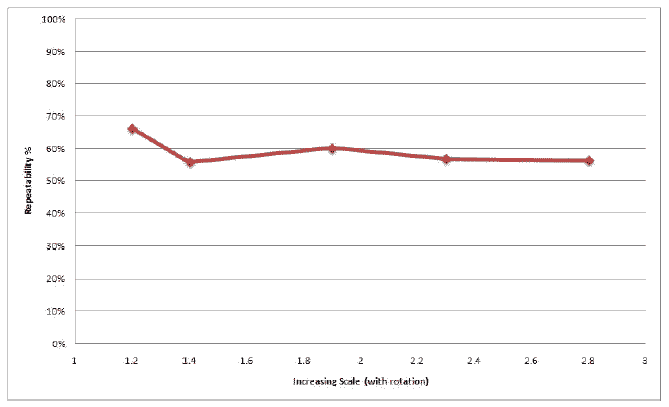
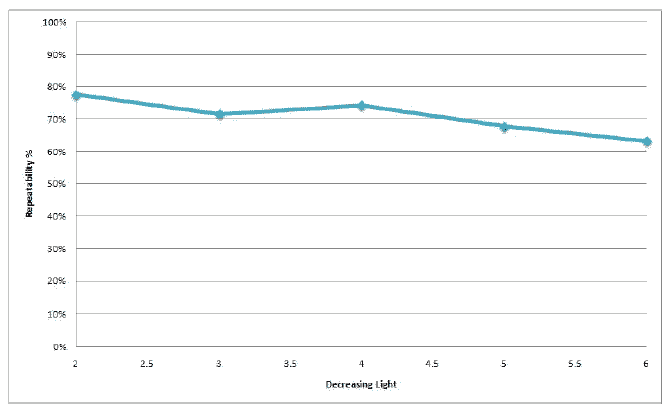
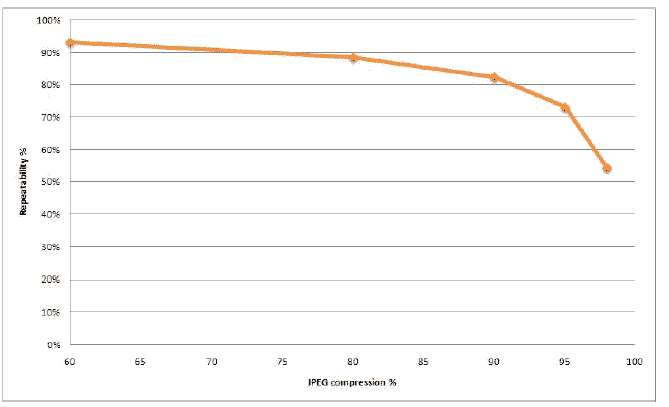
Как видно из тестов, метод ведет себя вполне стабильно.
Резкое падение процента распознавания при увеличении угла обзора на 45 градусов связано с тем, что SURF не инвариантен к аффинным преобразованиям. Падение при размытии и высокой степени сжатия JPEG объясняется потерей информации в изображении при этих преобразованиях. Хороший и стабильный результат наблюдается при вращении и изменении масштаба изображения. Неплохо метод справляется и с изменением яркости изображения.
Далее приведены еще несколько тестовых картинок, для наглядного представления о том, как работает SURF. Для локализации изображения использовался метод матрицы гомогенности.

На картинке слева находится образец, справа – сцена. Красные линии показывают максимально похожие особые точки образца и сцены. Красная трапеция – показывает обнаруженный на сцене объект.

Образец имеет в два раза больший масштаб, чем на сцене. Успешно локализован.

Образец был повернут на 45 градусов. Локализован.

Несмотря на большое количество ложных идентификаций, объект успешно локализован.

Образца нет на сцене. Алгоритм не нашел локализации.
Нужно отметить, несмотря на то, что SURF используется для поиска объектов на изображении, он сам работает не с объектами. SURF никак не выделяет объект из фона. Он рассматривает изображение как единое целое и ищет особенности этого изображения. При этом особенности могут быть как внутри объекта, так и на фоне, а также на точках границы объекта и фона. В связи с этим, метод плохо работает для объектов простой формы и без ярко выраженной текстуры. Внутри таких объектов, метод скорее всего не найдет особых точек. Точки будут найдены либо на границе объекта с фоном, либо вообще только на фоне. А это приведет к тому, что объект не сможет быть распознан в другом изображении, на другом фоне.

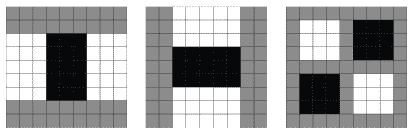
На картинке слева изображены простые геометрические фигуры на белом фоне. На картинке справа – те же фигуры на фоне природы.
На картинке хорошо видно, что обнаруженные признаки фигур почти нигде не совпадают. Это связано с тем, что ключевые точки были связаны с границей объекта и фона. Изменился фон – изменились ключевые точки.
Herbert Bay, Andreas Ess, Tinne Tuytelaars, and Luc Van Gool. Speeded-Up Robust Features (SURF)
Christopher Evans. Notes on the OpenSURF Library.
OpenSURF исходники на C#
Демонстрационное видео распознавания объектов с помощью SURF
Обнаружение устойчивых признаков изображения: метод SURF
Статья рассматривает алгоритм поиска и описания особых точек изображения SURF. Метод может применяться для сравнения изображений, поиска объектов на изображениях, 3D реконструкции.
Задача распознавания образов до сих пор не решена в полном объеме. Однако, в рамках существенных ограничений, есть методы, позволяющие приблизится к ее решению.
Среди различных родственных методов, был выбран для рассмотрения метод Speeded Up Robust Features (SURF), поскольку он является одним из самых эффективных и быстрых современных алгоритмов. Кроме того, SURF является распространенным методом, его реализации есть во многих математических библиотеках.
В первой части я опишу проблему в целом и обобщенные пути решения.
В дальнейшем описании я постараюсь придерживаться именно SURF, не отвлекаясь на родственные алгоритмы и не углубляясь в теоретическую базу. Вторая часть статьи скорее отвечает на вопрос «как оно работает?», чем на вопрос «почему этот алгоритм именно такой?». Теоретические обоснования можно почерпнуть из первоисточника, а также из списка литературы, приведенного в конце статьи.
Проблематика
Когда мы смотрим на окружающих нас лица людей, предметы, природу, мы не осознаем какой объем работы проделывает наш мозг, что бы обработать весь поток визуальной информации. Нам не составит труда найти знакомого нам человека на фотографии, или отличить здание от памятника. Казалось бы, наши компьютеры отлично могут хранить огромные объемы информации, картинки, видео и аудио файлы. Что мешает им с такой же легкостью найти фото нашего любимого человека из личной фотогалереи? Этому препятствует ряд моментов, которые мы здесь и перечислим.
Момент первый: Масштаб. Изображения имеют разный масштаб. Предметы, которые мы воспринимаем как одинаковые, на самом деле занимают разную площадь на разных изображениях.
Момент второй: Место. Интересующий нас объект может находиться в разных местах изображения.
Момент третий: Фон и помехи. Предмет, который мы воспринимаем как что-то отдельное, на изображении никак не выделен, и находится на фоне других предметов. Кроме того, изображение не идеально и может быть подвержено всякого рода искажениям и помехам.
Момент четвертый: Проекция, вращение и угол обзора. Изображение является лишь двумерной проекцией нашего трехмерного мира. Поэтому поворот объекта и изменение угла обзора кардинальным образом влияют на его двумерную проекцию — изображение. Один и тот же объект может давать совершенно разную картинку, в зависимости от поворота или расстояния до него.
Список можно было-бы продолжать еще долго. Но мы не будем этого делать.
Итак, даны два изображения, один из них будем считать образцом, другое – сценой. Задача сводится к определению факта наличия образца на сцене, и к его локализации. При этом образец на сцене может:
a) иметь другой масштаб
б) быть повернут в плоскости изображения
в) быть в произвольном месте сцены
г) может быть зашумлен, виден не полностью, частично заслонен другими предметами
д) может иметь отличную от образца яркость и контраст
е) его может не быть совсем
Возможны, конечно, и другие варианты. Однако мы будем решать только перечисленные пункты. Например, мы НЕ будем рассматривать вращение объекта вокруг произвольной оси. Поиск образца Софийского собора, но «с обратной стороны» — также выходит за рамки наших требований.
Но перейдем от задач к решениям.
Пути решения задачи
Не отвлекаясь на различные подходы к решению очерченных выше проблем сравнения образов, выберем один из них.
Самое простое и тривиальное решение заключается в следующем: возьмем образец в разных масштабах, повернем его на всевозможные углы, переберем всевозможные места на сцене, и будем все эти шаблоны попиксельно сравнивать со сценой.
Решение, как несложно понять, хорошее, но нереализуемое. И вот почему. Пусть образец и сцена имеют типичные размеры — порядка сотен пикселов по вертикали и горизонтали. Посчитав общее число всевозможных шаблонов, их поворотов, масштабов и локализации, а также умножив на число операций попиксельного сравнения, получим около триллиона (10^12) операций для поиска и локализации образца на сцене. Для какого нибудь Roadrunner это может и пустяки, но наши CoreDuo пока явно не дотягивают до такой производительности.
Кроме того, непосредственное сравнение образца со сценой может дать плохой результат, из-за шумов, искажений, заслонения, объектов фона.
Поэтому мы поступим хитрее. Выделим на образце некие ключевые точки и небольшие участки вокруг них. Ключевой точкой будем считать такую точку, которая имеет некие признаки, существенно отличающие ее от основной массы точек. Например, это могут быть края линий, небольшие круги, резкие перепады освещенности, углы и т.д. Предполагая, что ключевые точки присутствуют на образце всегда, то можно поиск образца свести к поиску на сцене ключевых точек образца. А поскольку ключевые точки сильно отличаются от основной массы точек, то их число будет существенно меньше, чем общее число точек образца.
В целом, принцип выбора ключевых точек не важен. Главное что бы их было не слишком много и они присутствовали на изображении образца всегда.
А почему вокруг точек выделяются малые участки? А вот почему. Чем меньше участок, тем меньше на него влияют крупномасштабные искажения. Так, если объект в целом, подвержен эффекту перспективы (то есть ближний край объекта имеет больший видимый размер, чем дальний), то для малого его участка явлением перспективы можно пренебречь и заменить на изменение масштаба. Аналогично, небольшой поворот объекта вокруг некоторой оси может сильно изменить картинку объекта в целом, но малые участки изменятся чуть-чуть.
Кроме того, если часть объекта выходит за край изображения или заслонена, то небольшие участки вокруг части ключевых точек будут видны целиком, что также позволяет их легче идентифицировать. А еще, если малые области лежат целиком внутри искомого объекта, то на них не оказывают никакого влияния объекты фона.
На рисунке показаны особые точки изображения в образце(слева) и на сцене(справа). Несмотря на то, что сцена имеет другой масштаб, угол обзора и частично заслонена другим объектом, ключевые точки достаточно точно идентифицируются.
С другой стороны, участок вокруг ключевой точки не должен быть слишком мал. Очень малые участки несут слишком мало информации об изображении и с большей вероятностью могут случайно совпадать между собой.
Обзор метода SURF
SURF решает две задачи – поиск особых точек изображения и создание их дескрипторов, инвариантных к масштабу и вращению. Это значит, что описание ключевой точки будет одинаково, даже если образец изменит размер и будет повернут (здесь и далее мы будем говорить только о вращении в плоскости изображения). Кроме того, сам поиск ключевых точек тоже должен обладать инвариантностью. Так, что бы повернутый объект сцены имел тот же набор ключевых точек, что и образец.
Метод ищет особые точки с помощью матрицы Гессе. Детерминант матрицы Гессе (т.н. гессиан) достигает экстремума в точках максимального изменения градиента яркости. Он хорошо детектирует пятна, углы и края линий.
На картинке – особые точки изображения здания, найденные с помощью матрицы Гессе. Диаметр круга показывает масштаб особой точки. Зеленая линия – направление градиента яркости.
Гессиан инвариантен относительно вращения. Но не инвариантен масштабу. Поэтому SURF использует разномасштабные фильтры для нахождения гессианов.
Для каждой ключевой точки считается направление максимального изменения яркости (градиент) и масштаб, взятый из масштабного коэффициента матрицы Гессе.
Градиент в точке вычисляется с помощью фильтров Хаара.
После нахождения ключевых точек, SURF формирует их дескрипторы. Дескриптор представляет собой набор из 64(либо 128) чисел для каждой ключевой точки. Эти числа отображают флуктуации градиента вокруг ключевой точки (что понимается под флуктуацией — рассмотрим ниже). Поскольку ключевая точка представляет собой максимум гессиана, то это гарантирует, что в окрестности точки должны быть участки с разными градиентами. Таким образом, обеспечивается дисперсия (различие) дескрипторов для разных ключевых точек.
Флуктуации градиента окрестностей ключевой точки считаются относительно направления градиента вокруг точки в целом (по всей окрестности ключевой точки). Таким образом, достигается инвариантность дескриптора относительно вращения. Размер же области, на которой считается дескриптор, определяется масштабом матрицы Гессе, что обеспечивает инвариантность относительно масштаба.
Флуктуации градиента также считаются с помощью фильтра Хаара.
Интегральное представление
Для эффективного вычисления фильтров Гессе и Хаара – используется интегральное представление изображений.
Если кратко, то интегральное представление является матрицей, размерность которой совпадает с размерностью исходного изображения, а элементы считаются по формуле:
Где I(i,j) – яркость пикселов исходного изображения.
Имея интегральную матрицу можно очень быстро вычислять сумму яркостей пикселов произвольных прямоугольных областей изображения, по формуле:
SumOfRect(ABCD) = II(A) + II(С) — II(B) — II(D)
Где ABCD – интересующий нас прямоугольник.
Вычисление матрицы Гессе
Обнаружение особых точек в SURF основано на вычислении детерминанта матрицы Гессе (гессиана).
Матрица Гессе для двумерной функции и ее детерминант определяется следующим образом:
Значение гессиана используется для нахождения локального минимума или максимума яркости изображения. В этих точках значение гессиана достигает экстремума.
На картинке видно, что особые точки (очерченные цветными кругами) представляют собой локальные экстремумы яркости изображения. Мелкие точки не распознаны как особые, из-за порогового отсечения по величине гессиана.
На рисунке показаны концы отрезка, распознанные как ключевые точки, с помощью матрицы Гессе.
Теоретически, вычисление матрицы Гессе сводится к нахождению Лапласиана Гауссиан. По сути, элементы матрицы Гессе вычисляются как свертка (сумма произведений) пикселов изображения на фильтры, изображенные на рисунке:
На рисунке изображены дискретизированные фильтры для нахождения четырех элементов матрицы Гессе (четвертый – совпадает с третьим, поскольку матрица Гессе симметрична). Фильтры имеют пространственный масштаб 9x9 пикселов. Темные участки соответствуют отрицательным значениям фильтра, светлые – положительным.
Однако, SURF не использует лапласиан гауссианы в том виде, который изображен на рисунке. Во-первых, по утверждению авторов, дискретизированный лапласиан гауссианы имеет довольно большой разброс значения детерминанта, при вращении образца (напомним, что в идеале гессиан должен быть инвариантен к вращению). Особенно детерминант «проседает» в районе поворота на 45 граудсов. А во-вторых, и это главное, фильтр для лапласиана гауссианы имеет непрерывный характер. Почти все пикселы фильтра имеют разные величины яркости. А это не позволяет эффективно использовать такой мощный механизм расчёта, как интегральную матрицу изображения.
Поэтому SURF использует бинаризированную аппроксимацию лапласиана гауссиан (авторы назвали его Fast-Hessian):
На рисунке изображены фильтры, используемые для нахождения матрицы Гессе в SURF. Белые области соответствуют значению +1, черные -2 (на третьем фильтре -1), серые – нулевые. Пространственный масштаб – 9x9 пикселов.
Этот фильтр более устойчив к вращению, и его можно эффективно вычислить с помощью интегральной матрицы.
Таким образом, в SURF, гессиан вычисляется так:
Где Dxx, Dyy, Dxy – свертки по фильтрам, изображенным на рисунке вверху. Коэффициент 0.9 имеет теоретическое обоснование, и корректирует приближенный характер вычислений.
Итак, для нахождения особых точек, SURF пробегается по пикселам изображения и ищет максимум гессиана. Способ нахождения локального максимума гессиана мы рассмотрим позднее. В методе задается пороговое значение гессиана. Если вычисленное значение для пиксела выше порога – пиксел рассматривается как кандидат на ключевую точку.
Тут еще полезно заметить следующее. Поскольку гессиан является производной, и зависит только от перепада яркости, но не от абсолютного ее уровня, то он инвариантен по отношению к сдвигу яркости изображения. Таким образом, изменение уровня освещения образца не влияет на обнаружение ключевых точек.
Кроме того, свойства гессиана таковы, что он достигает максимума, как в точке белого пятна на черном фоне, так и черного пятна на белом фоне. Таким образом, метод обнаруживает и темные, и светлые особенности изображения.
Метод распознает как светлые точки на темном фоне, так и темные точки на светлом фоне.
Шкалы
Как уже отмечалось, гессиан не инвариантен относительно масштаба. Это значит, что для одного и того же пиксела, гессиан может меняться при изменении масштаба фильтра. Решение этой проблемы только одно – перебирать различные масштабы фильтров и поочередно их применять к данному пикселу.
Из соображений симметрии и дискретизации, размер фильтра Fast-Hessian не может принимать произвольные значения. Допустимые размеры этого фильтра таковы (начиная с минимального): 9, 15, 21, 27 и так далее, с шагом 6. Однако, на практике, постепенно увеличивать размер фильтра на 6 — не выгодно, потому что для крупных масштабов шаг 6 оказывается слишком мелким, а фильтры — избыточными. Поэтому (и по некоторым другим причинам), SURF разбивает все множество масштабов на так называемые октавы. Каждая октава покрывает определенный интервал масштабов, и имеет свой характерный размер фильтра.
При этом если бы на октаву приходился только один фильтр, это было бы слишком грубым приближением. Кроме того, мы бы не могли найти локальный максимум гессиана, среди разных масштабов, в разных октавах. Ведь одна и та же точка может иметь несколько локальных максимумов гессиана, в разных масштабах. Это хорошо видно на картинке:
Рисунок показывает две ключевые точки разного масштаба в одной точке изображения.
Если мы будем искать максимум среди всех гессианов, по всем масштабам, то мы бы нашли только один из максимумов, в то время как их может быть несколько. Один – в одном масштабе, другой – в другом.
Исходя из перечисленного, октава содержит не один фильтр, а четыре фильтра, которые хорошо покрывают характерный масштаб октавы:
На рисунке показаны первые три октавы метода SURF. Цифры в прямоугольниках показывают размер фильтра Fast-Hessian. Логарифмическая шкала снизу – показывает масштабы, покрываемые октавами.
Шаг размера фильтра в первой октаве – составляет 6, во второй – 12, в третьей – 24 и так далее.
Как видим, октавы значительно перекрываются друг другом. Это увеличивает надежность нахождения локальных максимумов. Почему в октаве именно четыре фильтра станет ясно из следующей главы.
Возникает вопрос, а сколько собственно октав достаточно для покрытия множества особых точек разных масштабов? Теоретически, масштабы бесконечны, однако в реальных изображениях, они вполне конечны, и основная масса сосредоточена в интервале от 1 до 10 (по данным авторов метода). Для покрытия этого диапазона достаточно четырех октав. Плюс добавляется одна или две октавы для покрытия бОльших масштабов. Итого, используется 5-6 октав. Теоретически, этого вполне достаточно для покрытия всевозможных масштабов на изображении 1024x768 пикселов.
Нахождение локального максимума гессиана
Для нахождения локального максимума гессиана, используется так называемый метод соседних точек 3x3x3.
Его смысл понятен из рисунка ниже:
Пиксел, помеченный крестиком считается локальным максимумом, если его гессиан больше чем у любого его соседа в его масштабе, а также больше любого из соседей масштабом меньше и масштабом больше (всего 26 соседей).
Исходя из такого определения локального максимума, понятно, что октава должна содержать не менее трех фильтров, иначе мы не сможем определить факт нахождения локального максимума гессиана внутри октавы.
Отметим еще такой момент. Фильтры октавы считаются не для всех пикселов подряд. Первая октава считается для каждого второго пиксела изображения. Вторая – для каждого четвертого, третья – для каждого восьмого и так далее. Смысл понятен – две точки с расстоянием 2 не могут содержать более одного максимума масштаба 2, 3 или более высоких масштабов. Поэтому нет смысла перебирать все точки изображения, для нахождения максимума масштаба 3, например.
Удвоение шага пикселов для октав позволяет экономить при расчёте фильтров. Как вы наверно уже заметили, размеры фильтров в октавах повторяются. Так, например, фильтр размером 27 присутствует в трех октавах. Так вот, при вычислениях, этот фильтр будет считаться только для первой октавы. Вторая и третья – просто используют расчёты первой октавы. А удвоение шага пикселов гарантирует, что точки в которых нужно считать гессиан, уже были просчитаны предыдущей октавой.
Поэтому, несмотря на то, что октава содержит четыре фильтра, на самом деле каждая октава(кроме первой) считает только два характерных для нее размера, два других – всегда можно взять из предыдущих октав. Первая же октава вынуждена считать все четыре своих фильтра.
Итак, после нахождения максимального гессиана методом соседних точек 3x3x3, мы нашли пиксел в котором этот максимум достигается. Однако, поскольку, октава перебирает не все точки изображения, то истинный максимум может не совпадать с найденным пикселом, а лежать где-то рядом, в соседних пикселах.
Для нахождения точки истинного максимума, используется интерполирование найденных гессианов куба 3x3x3 квадратичной функцией. Далее, вычисляется производная (методом конечных разностей соседних точек). Если она близка к нулю – мы в точке истинного максимума. Если производная велика – сдвигаемся в сторону ее уменьшения, и повторяем итерацию, до тех пор пока производная не станет меньше заданного порога. Если в процессе итераций мы отходим от начальной точки слишком далеко, то это считается ложным максимумом, и точка больше не считается особой.
Нахождение ориентации особой точки
Для инвариантности вычисления дескрипторов особой точки, которые будут рассмотрены ниже, требуется определить преобладающую ориентацию перепадов яркости в особой точке. Это понятие близко к понятию градиента, но SURF использует немного другой алгоритм нахождения вектора ориентации.
Сначала, вычисляются точечные градиенты в пикселах, соседних с особой точкой. Для рассмотрения берутся пикселы в окружности радиуса 6s вокруг особой точки. Где s – масштаб особой точки. Для первой октавы берутся точки из окрестности радиусом 12.
Для вычисления градиента, используется фильтр Хаара. Размер фильтра берется равным 4s, где s – масштаб особой точки. Вид фильтров Хаара показан на картинке:
Фильтры Хаара. Черные области имеют значения -1, белые +1.
Фильтры Хаара дают точечное значение перепада яркости по оси X и Y соответственно. Поскольку фильтры Хаара имеют прямоугольную форму, их значения легко считаются с помощью интегральной матрицы. Для расчёта одного фильтра произвольного размера требуется всего 6 операций.
Значения вейвлета Хаара dX и dY для каждой точки умножаются на вес и запоминаются в массиве. Вес определяется как значение гауссианы с центром в особой точке и сигмой равной 2s. Взвешивание на гауссиане необходимо для отсечения случайных помех на далеких от особой точки расстояниях.
Далее, все найденные значения dX и dY, условно наносятся в виде точек на плоскость, как показано на рисунке:
На рисунке показаны все найденные градиенты в виде точек в пространстве dXdY.
Далее, берется угловое окно (показано серым на рисунке) размером π/3, и вращается вокруг центра координат. Выбирается такое положение окна, при котором длина суммарного вектора для попавших в окно точек – максимальна. Вычисленный таким образом вектор нормируется и принимается как приоритетное направление в области особой точки.
Манипуляции с окном нужны для уменьшения влияния шумовых точек. Ниже на рисунке приведен пример градиента при идеальном крае, и при крае с шумом:
Как видим, шум дает дополнительные градиенты в направлениях, не совпадающих с направлением основного градиента. Использование окна позволяет отсечь такие шумовые точки, и более точно вычислить истинный градиент.
Отметим, что не всегда требуется инвариантность дескрипторов относительно вращения. Метод SURF имеет модификацию, в которой ориентация особых точек не рассчитывается. Такая модификация позволяет надежно идентифицировать точки, повернутые не более чем на ±15 градусов.
Вычисление дескриптора особой точки
Дескриптор представляют собой массив из 64 (в расширенной версии 128) чисел, позволяющих идентифицировать особую точку. Дескрипторы одной и той же особой точки на образце и на сцене должны примерно совпадать. Метод расчета дескриптора таков, что он не зависит от вращения и масштаба.
Для вычисления дескриптора, вокруг особой точки формируется прямоугольная область, имеющая размер 20s, где s – масштаб в котором была найдена особая точка. Для первой октавы, область имеет размер 40x40 пикселов. Квадрат ориентируется вдоль приоритетного направления, вычисленного для особой точки.
Дескриптор считается как описание градиента для 16 квадрантов вокруг особой точки.
Далее, квадрат разбивается на 16 более мелких квадрантов, как показано на рисунке. В каждом квадранте берется регулярная сетка 5x5 и для точки сетки ищется градиент, с помощью фильтра Хаара. Размер фильтра Хаара берется равным 2s, и для первой октавы составляет 4x4.
Следует отметить, что при расчёте фильтра Хаара, изображение не поворачивается, фильтр считается в обычных координатах изображения. А вот полученные координаты градиента (dX,dY) поворачиваются на угол, соответствующий ориентации квадрата.
Итого, для вычисления дескриптора особой точки, нужно вычислить 25 фильтров Хаара, в каждом из 16 квадрантов. Итого, 400 фильтров Хаара. Учитывая, что на фильтр нужно 6 операций, выходит, что дескриптор обойдется минимум в 2400 операций.
После нахождения 25 точечных градиента квадранта, вычисляются четыре величины, которые собственно и являются компонентами дескриптора:
∑dX, ∑|dX|, ∑dY, ∑|dY|
Две из них есть просто суммарный градиент по квадранту, а две других – сумма модулей точечных градиентов.
На рисунке показано поведение этих величин для разных участков изображений.
Рисунок показывает поведение дескриптора для разных изображений. Для равномерных областей – все значения близки к нулю. Для повторяющихся вертикальных полосок – все величины, кроме второй близки к нулю. При увеличении яркости в направлении оси X, две первые компоненты имеют большие значения.
Четыре компонента на каждый квадрант, и 16 квадрантов, дают 64 компонента дескриптора для всей области особой точки. При занесении в массив, значения дескрипторов взвешиваются на гауссиану, с центром в особой точке и с сигмой 3.3s. Это нужно для большей устойчивости дескриптора к шумам в удаленных от особой точки областях.
Плюс к дескриптору, для описания точки используется знак следа матрицы Гессе, то есть величина sign(Dxx+Dyy). Для светлых точек на темном фоне, след отрицателен, для темных точек на светлом фоне – положителен. Таким образом, SURF различает светлые и темные пятна.
На картинке показаны особые точки изображения. Зеленая линия показывает характерное направление для особой точки. Синий цвет окружности показывает положительный след матрицы Гессе, красный – отрицательный след.
Примеры и тесты
Ниже приведен набор тестовых изображений. Первая колонка показывает изображение граффити, снятое под разным углом зрения. Вторая колонка содержит фотографии с размытием. Третья – поворот и изменение масштаба. Четвертая содержит изображения с разным уровнем яркости. Пятая – идентичное изображение, но с разным качеством сжатия JPEG.
Далее приведены результаты тестирования. По вертикали отложен процент точек, которые были правильно идентифицированы.
Как видно из тестов, метод ведет себя вполне стабильно.
Резкое падение процента распознавания при увеличении угла обзора на 45 градусов связано с тем, что SURF не инвариантен к аффинным преобразованиям. Падение при размытии и высокой степени сжатия JPEG объясняется потерей информации в изображении при этих преобразованиях. Хороший и стабильный результат наблюдается при вращении и изменении масштаба изображения. Неплохо метод справляется и с изменением яркости изображения.
Далее приведены еще несколько тестовых картинок, для наглядного представления о том, как работает SURF. Для локализации изображения использовался метод матрицы гомогенности.
На картинке слева находится образец, справа – сцена. Красные линии показывают максимально похожие особые точки образца и сцены. Красная трапеция – показывает обнаруженный на сцене объект.
Образец имеет в два раза больший масштаб, чем на сцене. Успешно локализован.
Образец был повернут на 45 градусов. Локализован.
Несмотря на большое количество ложных идентификаций, объект успешно локализован.
Образца нет на сцене. Алгоритм не нашел локализации.
Недостатки метода
Нужно отметить, несмотря на то, что SURF используется для поиска объектов на изображении, он сам работает не с объектами. SURF никак не выделяет объект из фона. Он рассматривает изображение как единое целое и ищет особенности этого изображения. При этом особенности могут быть как внутри объекта, так и на фоне, а также на точках границы объекта и фона. В связи с этим, метод плохо работает для объектов простой формы и без ярко выраженной текстуры. Внутри таких объектов, метод скорее всего не найдет особых точек. Точки будут найдены либо на границе объекта с фоном, либо вообще только на фоне. А это приведет к тому, что объект не сможет быть распознан в другом изображении, на другом фоне.
На картинке слева изображены простые геометрические фигуры на белом фоне. На картинке справа – те же фигуры на фоне природы.
На картинке хорошо видно, что обнаруженные признаки фигур почти нигде не совпадают. Это связано с тем, что ключевые точки были связаны с границей объекта и фона. Изменился фон – изменились ключевые точки.
Использованные источники
Herbert Bay, Andreas Ess, Tinne Tuytelaars, and Luc Van Gool. Speeded-Up Robust Features (SURF)
Christopher Evans. Notes on the OpenSURF Library.
OpenSURF исходники на C#
Демонстрационное видео распознавания объектов с помощью SURF
комментарии (55)

Спасибо. Отличная и познавательная статья. А вот у нас только в этом семестре начинается курс распознавания изображений. Может блесну умом-разумом =)

А где вы учитесь?
Киевский Политех.

оО не у Игнатенко случайно? )))
Бугага. У Игнатенко =)
Суровый преподаватель…


единственное, для чего будут применять поисковики по фотографиям с алгоритмами распознавания 95% жителей сети — искать интимные фотки знакомых девочек

Вы правы, но остальные 5% тоже заслуживают внимания. Например, автоматическое распознавание бактерий в анализах крови, распознавание дорожных знаков автомобилями. Даже крупномасштабная структура вселенной исследовалась с помощью вейвлет анализа.

Вы не пробовали Google Goggles на Андроиде. Поверьте — сфотографировать фреску на стене и через пару секунд читать что это… или сфотографировать здание и опять же через секунду знать что это — это впечатляет больше, чем голые фотографии…
Кроме того SURF не особо пригоден для распознавания лиц — он не для того создавался. Он создан найти одинаковые точки на двух фотографиях, снявших примерно одно и то же (для 3D реконструкции), ну или найти похожие объекты на двух фотках. Но, подозреваю, что для него все лица примерно похожие.
Кроме того SURF не особо пригоден для распознавания лиц — он не для того создавался. Он создан найти одинаковые точки на двух фотографиях, снявших примерно одно и то же (для 3D реконструкции), ну или найти похожие объекты на двух фотках. Но, подозреваю, что для него все лица примерно похожие.
Приятно когда мат аппарат применяется к таким, казалось бы неформализуемым вещам.
Спасибо. Очень интересно.
Спасибо. Очень интересно.

ребаный йод… это даже не на вечер, а, пожалуй, до выходных…
И, конечно же, Спасибо! :)
И, конечно же, Спасибо! :)
Метод хороший, но очень медленный. Пытался использовать на больших объемах данных. Нужны дополнительные эвристики.

медленный? значит вы SIFT не пробывали :)
SURF один из самых быстрых, среди аналогов. По крайней мере авторы утверждают, что он ничем не уступает, а по скорости превосходит аналоги.

Насколько я помню, он сравним по скорости и качеству с SIFT. Основной плюс для коммерческого применения — более свободная лицензия.
SURF также запатентован, выяснилось это не очень-то давно.
v3.espacenet.com/publicationDetails/biblio?CC=EP&NR=2027558A2&KC=A2&FT=D&date=20090225&DB=EPODOC&locale=en_V3
И вот еще от оригинальных авторов SURF:
www.google.ru/patents/about?id=ST_KAAAAEBAJ
v3.espacenet.com/publicationDetails/biblio?CC=EP&NR=2027558A2&KC=A2&FT=D&date=20090225&DB=EPODOC&locale=en_V3
И вот еще от оригинальных авторов SURF:
www.google.ru/patents/about?id=ST_KAAAAEBAJ
Так что в итоге?
На каких условиях его можно использовать?
На каких условиях его можно использовать?
Я не юрист, но факт наличия патента всех сразу же отпугивает (даже OpenCV формирует план отхода от SURF).
В академических целях — скорее всего все равно (для сравнения эффективности).
В коммерческих — думаю надо связываться с авторами и получать у них разрешение.
В академических целях — скорее всего все равно (для сравнения эффективности).
В коммерческих — думаю надо связываться с авторами и получать у них разрешение.

Спасибо за статью! Всё собирался выложить описание SIFT-а :)
Почему-то мне казалось, что SURF использует для нахождения ключевых точек алгоритм как и у SIFT-а (через DoG), а различие только в расчёте дескрипторов.
Нужно отметить, что SURF уже реализован в OpenCV (samples\c\find_obj.cpp)
Почему-то мне казалось, что SURF использует для нахождения ключевых точек алгоритм как и у SIFT-а (через DoG), а различие только в расчёте дескрипторов.
Нужно отметить, что SURF уже реализован в OpenCV (samples\c\find_obj.cpp)
В OpenCV он взят из VLFeat (vlfeat.org). Ещё там добавили MSER.
> Всё собирался выложить описание SIFT-а
Выкладывайте!
SIFT меньше чувствителен к афинным преобразованиям. Будут интерестны детали.
Выкладывайте!
SIFT меньше чувствителен к афинным преобразованиям. Будут интерестны детали.
Только имейте в виду, что SIFT — крайне запатентованный алгоритм — его точно нельзя использовать ни в каких коммерческих целях.
Я находил в сети свободный почти SIFT алгоритм с некоторыми отличаями в дескрипторах. И потом — патенты патентами, а знания знаниями. В случай комерческой реализации просто надо покупать лицензию.
наконец-то начинаю понимать, как работает tineye!

Да что вы знаете! Тысяча индуссов, с оплатой 10 долларов в час
(на всех).
(на всех).
TinEye работает немного по-другому. Там используются алгоритмы хеширования изображений. Поиск по 480 миллионам картинок за секунду (как это обещают авторы TinEye) невозможен с использованием SIFT, SURF и подобных.
Пример работы алгоритмов хеширования изображений можно найти тут: www.phash.org/ (там есть демо и три алгоритма).
Какой именно хеш используют TinEye — мне не известно. Однако по хешу искать можно очень быстро.
Пример работы алгоритмов хеширования изображений можно найти тут: www.phash.org/ (там есть демо и три алгоритма).
Какой именно хеш используют TinEye — мне не известно. Однако по хешу искать можно очень быстро.

Чрезвычайно содержательный пост, уже в избранном. Слава роботам!
а можно подробнее написать статью про вейвлеты, но с ориентиром для чайников?
как я понимаю, они используются и в компрессии JPEG-ах?
очень здорово, что появляются такие статьи на Хабре, сначала Декодирование JPEG для чайников. Теперь ваша
как я понимаю, они используются и в компрессии JPEG-ах?
очень здорово, что появляются такие статьи на Хабре, сначала Декодирование JPEG для чайников. Теперь ваша
В компрессии JPEG используются не вейвлеты, а дискретное косинус-преобразование. А вот в JPEG2000 да, именно вейвлеты.
>а можно подробнее написать статью про вейвлеты, но с ориентиром для чайников?
Можно… Только с темой нужно определиться. Про что именно писать? Абстрактные модели не очень интересны. Нужна конкретная задача.
Можно… Только с темой нужно определиться. Про что именно писать? Абстрактные модели не очень интересны. Нужна конкретная задача.


Интересно, насколько хорошо применим этот метод для распознавания каптчи?
маловероятно. вернее сказать — этот метод точно не для этого.
Метод предназначен для обнаружения одинаковых объектов.
А капча как раз наоброт, старается сделать картинки как можно более непохожими на образец.
Здесь лучше всего работают нейросетевые методы.
А капча как раз наоброт, старается сделать картинки как можно более непохожими на образец.
Здесь лучше всего работают нейросетевые методы.

Спасибо что делитесь опытом. С интересом читаю ваши статьи.

Хорошая статья!
Сейчас ведуться разработки в этой сфере для идетификации обьектов и создания систем аргументированой реальности.
Существует ещё несколько алгоритмов для идетификации обьектов на изображениях. Пол года назад увлёкся данным вопросом и нашёл несколько достаточно простых, но итересных решений поиска контуров в изображениях с помощью сравнения цвета, яркости и т.д. пиксела с его соседями. Данный метод может помочь в распозновании и фильрации изображений.
Сейчас ведуться разработки в этой сфере для идетификации обьектов и создания систем аргументированой реальности.
Существует ещё несколько алгоритмов для идетификации обьектов на изображениях. Пол года назад увлёкся данным вопросом и нашёл несколько достаточно простых, но итересных решений поиска контуров в изображениях с помощью сравнения цвета, яркости и т.д. пиксела с его соседями. Данный метод может помочь в распозновании и фильрации изображений.

Интересно! Вы не могли ещё что-нибудь посоветовать по теме, если не трудно про методы распознавания?
Может и мог бы. Только тут все зависит от конкретной задачи. Методов «распознавания всего» пока не придумали :)
Ещё с помощью метода, с некоторой доработкой, можно отслеживать положение камеры в пространстве, относительно неподвижного объекта. Снимаете например известный объект на камеру вашего телефона, и получаете свои координаты с некоторой точностью.
Больше таких статей! Огромное спасибо автору за труд. Продолжайте в том же духе, пожалуйста :)


Не самый производительный алгоритм. Можно обходиться без вычисления градиентов, остановившись на полярном представлении гауссовых точек. Метод, конечно, даёт коллизии, зато
1. считается раз в 5 быстрее
2. даёт функцию ранжирования похожести изображения
1. считается раз в 5 быстрее
2. даёт функцию ранжирования похожести изображения
There's definately a lot to learn about this subject. I love all of the points you made.
ReplyDeleteInteresting post. I Have Been wondering about this issue, so thanks for posting. Pretty cool post.It 's really very nice and Useful post.Thanks 검증사이트
ReplyDelete